Trying out GraphQL
 Nikolay Anguelov
Nikolay AnguelovIntroduction
Since it was open sourced by Facebook in 2015, GraphQL has shaken up the status quo of data retrieval and given engineers an alternative to REST. Underpinned by the concept of declarative data fetching and the promise of 'consistently predictable results', GraphQL challenges the long standing reliance on REST APIs and offers a brand new way of doing things, coming with both its benefits and drawbacks.
As a company that always keeps an eye on the hottest trends in the tech industry and is not afraid to embrace change within our tech stack, the move to test the waters with GraphQL was one that was given a warm reception here at Lendable.

The Credit & Data Science team @ Lendable
There are many engineering teams at Lendable and the Credit & Data Science team take ownership of many of the internal applications and services that make Lendable tick. While our main engineering teams are busy building Lendable's core products - the loans product, car finance and credit card - our data scientists and analysts work behind the scenes to build and deploy the models that underpin credit decisions for a prospective customer when they apply for credit with us.
The engineers on the Credit & Data Science team also interface with non-engineering teams to provide them bespoke tools to assist with their day to day work. Over the years we’ve built and maintained tools to track loans performance, credit card spending metrics, quality assurance checks, and so much more. We work hard to make sure we support all teams in the company and fill in the gaps left by some of the enterprise software tools we use.
If you want to find out more about the Credit & Data Science team, check out Lead Data Engineer Ben Smith's post on data science at Lendable!
Introduction to GraphQL
You may probably be wondering why GraphQL is even necessary? What advantages does it provide over the standard REST API?
With the REST API, you have two routes you can take:
- Create generic endpoints like
/usersor/transactions, and allow engineers to filter items based on either path parameters, query string variables, or body parameters. This approach is fine, but typically you will end up over/under fetching data, whether it be in the total number of entries returned, or simply obtaining more/less columns than you really need. Obviously as you scale your application, over/under fetching data will become a bottleneck for your performance. - Or you could go down the route of creating custom endpoints which are tailor made to your data needs and return only the fields required. This solves the problem of not getting exactly the data you want, but now your application will be flooded with so many different endpoints and bespoke SQL queries that it becomes messy, unmanageable, and, most importantly, unscalable.
GraphQL comes in and solves these problem by allowing you to fetch only the fields you need, while at the same time allowing you easily fetch related resources, saving you the headache of data munging on the frontend to aggregate data into the desired shape. GraphQL also declares only one endpoint /graphql, and all requests go through this endpoint. Engineers then define queries to indicate what data they would like returned.
To see a basic example, assume you have a customer model defined in SQLAlchemy as such:
from sql_alchemy.ext.declarative import declarative_base as Base
from sqlalechemy import Column, DateTime, String, Integer
class Customer(Base):
__tablename__ = "customers"
id = Column(Interger, primary_key=True)
title = Column(String(64))
first_name = Column(String(64))
middle_name = Column(String(64))
last_name = Column(String(64))
suffix = Column(String(64))
date_of_birth = Column(DateTime)
created = Column(DateTime)
product = Column(String(64))
# Other Customer fields
Say you want to query your API’s /customers endpoint to fetch some customer data, namely only the first-name, last-name, and date-of-birth fields. In a standard API, you’d retrieve each customer (or a subset of them if you are filtering),and you would then receive all the other fields that are defined on the model, things like title, middle name, suffix, etc. Since you only want first name, last name, and date of birth, you’re going to be sending more data over the network than necessary. For one customer object this may not be a big deal, but if you need this for 10,000 customers or perhaps 1,000,000 customers, then you will suffer some serious performance penalties. GraphQL makes it easy to grab exactly what you need, with a simple query such as:
query {
allCustomers {
firstName
lastName
dateOfBirth
}
}
In addition, whenever you need to fetch more or less data from your API, you simply change your query in your frontend code, no backend changes required. Of course if you need to add new fields which were previously undefined, then you will need to change the underlying GraphQL model.
GraphQL also has the advantage of not requiring you to version your APIs, which can be great for clients which may be on an older version of your application. Typically older fields are not removed from the schema to allow for clients who have not updated to the newer version to continue using your API. Clients on the newer versions can pull from the new schema definition and this way you can easily service all users without forcing breaking changes upon users with older versions.
Setting up GraphQL on the backend
Since this would be the first of its kind API at the company, an internal tool was selected for testing things out, as it’s relatively low risk and said tool was in desperate need of an overhaul. The tool is a simple Python application which uses SQLAlchemy’s ORM to manage the database. This actually made it extremely quick to migrate to GraphQL as the Graphene python package allowed me to create the necessary GraphQL classes by declaring wrappers around the original models.
Creating new GraphQL models takes just a few simple lines of code thanks to the Graphene package and allowed me to quickly get things up and running:
import graphene
from graphene_sqlalchemy import SQLAlchemyObjectType
from my_models_file import SomeModel
class SomeModelGraphql(SQLAlchemyObjectType):
class Meta:
model = SomeModel
interfaces = (graphene.relay.Node, )
Once all the models were defined, I was then able to create the underlying queries and mutations, ie. the GET and POST/DELETE/PATCH/etc. equivalents, for the API.
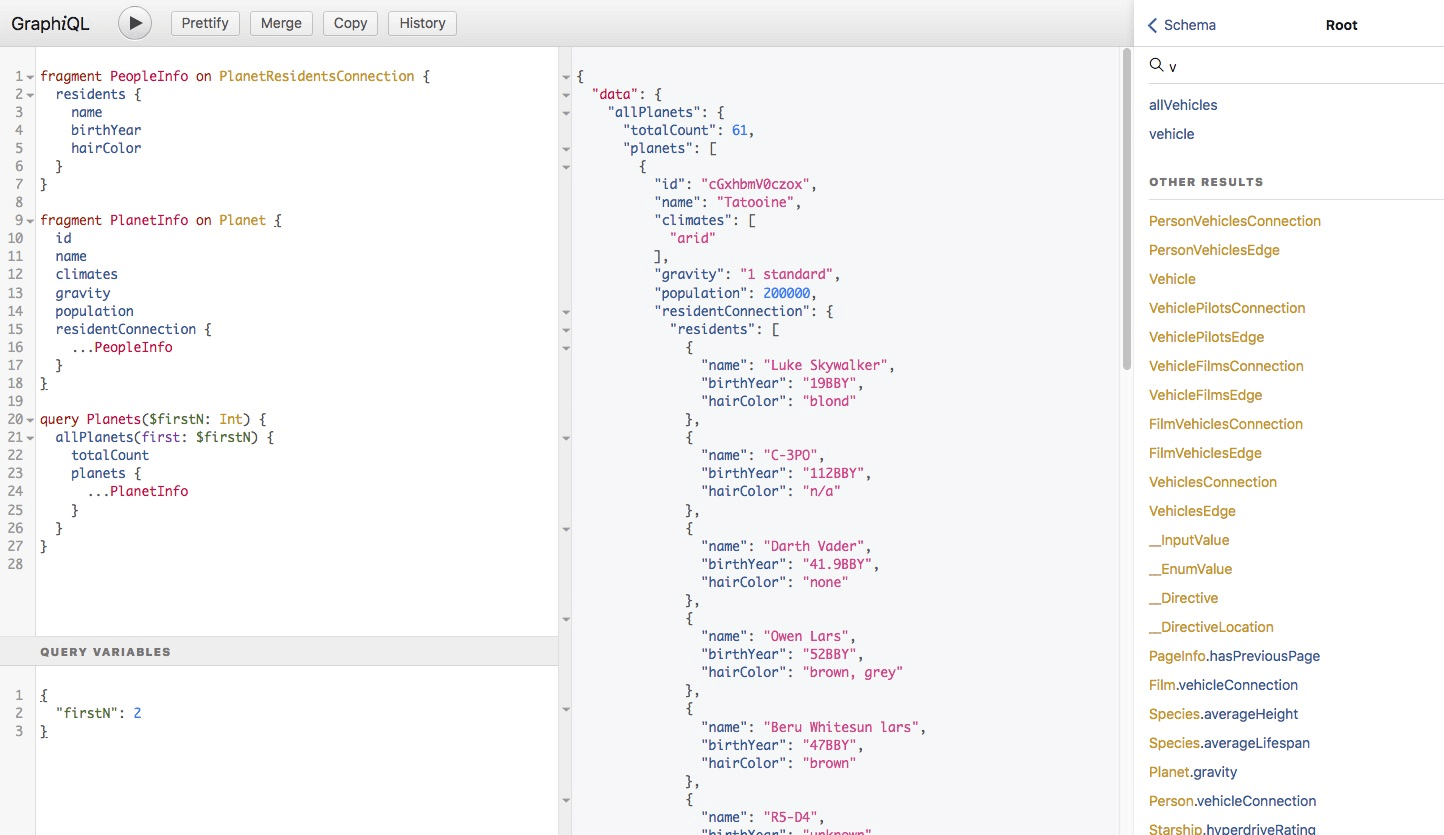
GraphQL ships with an amazing developer tool called GraphiQL, which is a neat little query environment where you can test your API. It allows you to execute GraphQL code, explore your declared schemas, and see which queries and mutations are defined for your endpoint.
Due to the ease of migration provided by Graphene, I was able to migrate our entire backend to GraphQL in less than a week. There were some complex CRUD features that needed to be replicated, but for anyone with a relatively simple backend, it should be even quicker to set up!
One thing to watch out for when migrating your own backend to GraphQL is the notorious N + 1 problem, whereby the foreign key relationships in your data execute far more queries than necessary when fetching from the server. Typically this problem can be addressed by using something called a dataloader, or if you are also using SQLAlchemy, you can actually just tell SQLAlchemy to handle this for you (For reference, look into the lazy parameter of your relationship fields in a model class).
GraphQL on the frontend
So I’ve now got a GraphQL endpoint which has all the same functionality of the prior API. What now?
In order to actually consume the data from a GraphQL endpoint, one must also change their frontend application to connect to, query from, and render the data returned. Unfortunately, this is by far the hardest part of the migration, as there’s a whole lot more that goes into this than simply sending requests to the GraphQL endpoint.

There are many approaches to querying a GraphQL endpoint, but I went with Facebook's Relay package for a multitude of reasons:
- Relay is extremely opinionated and forces you to follow strict rules for building your application. While these can make it a pain for first time users, the benefit gained is an extremely consistent and predictable interface for interacting with your GraphQL API.
- The Relay compiler analyses the GraphQL you’ve embedded in your frontend code and automatically generates the corresponding type declarations for you. This is an amazing feature and saves you dev time declaring interfaces, as well as all the benefits of type safety for your code.
- Relay allows you to aggregate as many of your data queries into one as possible, and will pre-calculate the most optimised query to send to the endpoint, saving you network bandwidth.
One of the coolest features of Relay I’ve experienced is the ability to perform optimistic updates on the UI. What this essentially means is that when an action that mutates the graph is made (ie a POST/DELETE/PATCH/etc.), then you can ask Relay to modify it’s internal data store and re-render the UI under the assumption that the request was successful.
Relay will augment the necessary resource and re-render under the assumption that the request will succeed. This way you get the desired UI changes without waiting for the response from the server. This is great if the action you need to perform on the backend is not fast and you’d like the user not to wait on the UI to acknowledge the action. An engineer can then define the logic for what is supposed to happen when the request is successful. Once the backend responds that the request went through, the UI will re-render with the new logic, or revert back to the original state, should the request have failed.
Another great feature of Relay is its seamless support for pagination of entries. Though there is a bit more work on the backend to configure the connections and Relay node types, once set up, Relay’s full power begins to shine. Each object in Relay has its own globally unique ID and this allows Relay to easy paginate results based on the concept of cursors. Say you’re building a data table to render some metadata about the users of your system. Instead of fetching all the data at once or trying to write a complex endpoint to handle pagination, Relay supports this out of the box and can paginate both forwards and backwards. Each time you need to load the next page, Relay will handle this for you without any headache, simply use the provided hasNext or hasPrevious variables exposed by the Pagination helper hook to ensure there is more data to fetch and then ask Relay to fetch N additional entries.
Relay gotchas
While there are many great features to using Relay, I did find it a bit difficult to learn in the beginning. The most up to date documentation (v11.0.0 at the time of writing) is focused on using functional components & the Hooks API inside React, whereas our codebase contains some class based components. Relay fully supports class based components but you’ll have to dig through an older version of the documentation to find the information you’re looking for.
Unfortunately, the documentation can be overwhelming and there are few resources on the internet that really give a step-by-step guide of how to build a Relay project from the ground up. The one amazing resource I was able to find and relied on heavily was this guide. Many of the lessons learned were from trial and error or desperately searching through StackOverflow to find answers. The steep learning curve definitely makes this a tricky technology to learn.
Finally, because Relay is so opinionated and follows the paradigm of 'you only get what you ask for', components that don’t specifically ask for a piece of data will have no ability to access or view it, even if it is passed down from a higher order component as props. Any component that wants to consume data from the GraphQL API will need to declare a fragment describing the exact shape of the data required. Whatever fields you ask for is what you receive, nothing more and nothing less.
This makes it difficult to debug because it is difficult to follow the data flow down your component tree as intermediate components will not even be able to console.log() data received unless they specifically define a fragment. Thus it may take a while to understand how to properly create your components in order to work inside of Relay’s strict requirements.
Conclusion
In summary, my first exposure to GraphQL and Relay was positive, but had some challenges described above. It was our team’s first trial of GraphQL, so we had no internal expertise and I had to figure out many things by myself.
After a good two weeks of trial and error, I was finally able to fully re-create the backend and frontend functionalities of our old application and transform it into a slick, well-oiled machine, which utilises some of the newest and greatest tech out there.
After this migration, the Credit & Data Science team has been impressed by the benefits of this dynamic duo and will aim to use these technologies for our projects going forward where applicable. Hopefully this will serve to drive an argument for wider adoption across the company for existing APIs that could benefit from the migration.
The power of GraphQL and Relay is immense, though it does come with a steep learning curve and an extremely in-flexible way of doing things. When it comes to application development using this tech stack, is is really opionated and that’s something you’ll need to accept (and eventually come to love).
I’ll link below all the resources mentioned so that you can investigate for yourself whether GraphQL and Relay are viable options for your projects! I hope you’ve enjoyed this brief introduction to how the Credit & Data Science team are using GraphQL and Relay at Lendable.